

Яндекс.XML – это сервис Яндекса, который позволяет разработчикам получить доступ к данным поисковой системы Яндекс. С помощью Яндекс.XML вы можете получать информацию о результатах поиска, а также о различных параметрах, связанных с сайтом.
Одним из ключевых элементов поисковой системы Яндекс являются сниппеты – краткие описания страниц, которые отображаются в результатах поиска. Сниппеты помогают пользователям быстро понять, о чем идет речь на странице, и решить, стоит ли им переходить по ссылке.
Используя Яндекс.XML и парсер сниппета, разработчики могут получить не только полностью заготовленный сниппет, но и дополнительные параметры, такие как заголовок страницы, URL, дата последнего обновления и многое другое. Это позволяет оптимизировать сайт для поисковых систем и повысить его видимость и привлекательность для пользователей.
В данной статье мы рассмотрим подробно использование Яндекс.XML на примере парсера сниппета поисковой системы Яндекс, а также расскажем о том, какие возможности предоставляет этот сервис и как его использовать для улучшения SEO-оптимизации вашего сайта.
Используем Яндекс.XML на примере парсера сниппета поисковой системы Яндекс
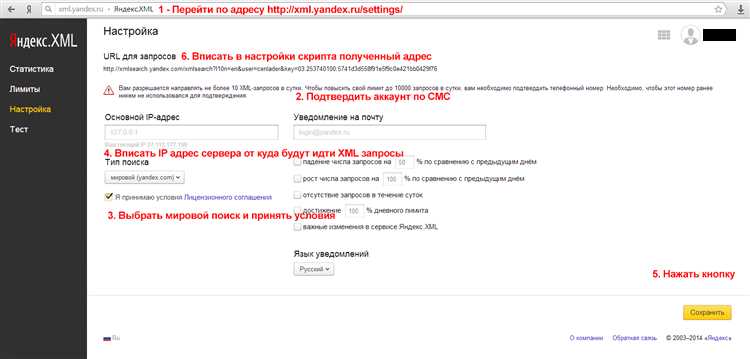
Для использования Яндекс.XML необходимо создать аккаунт в Яндексе, зарегистрировать свой сайт в Яндекс.Вебмастере и получить специальный ключ доступа к API Яндекс.XML. После этого можно отправлять запросы к Яндексу и получать информацию о своих страницах в поисковой системе.
Пример использования Яндекс.XML на парсере сниппета
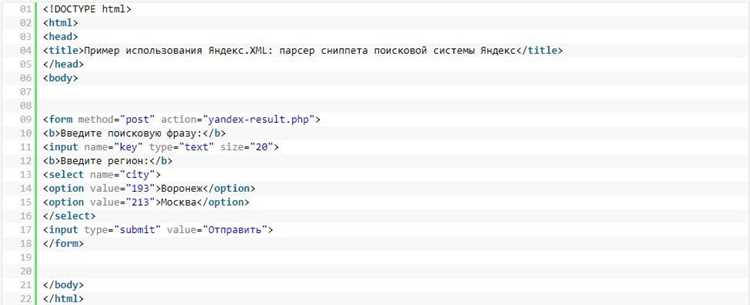
Давайте рассмотрим пример использования Яндекс.XML на парсере сниппета поисковой системы Яндекс. Допустим, у нас есть страница сайта, которая отображается в поисковой выдаче Яндекса. Наша задача — получить сниппет этой страницы, то есть описание и заголовок, который отображается в поисковой выдаче.
Для этого мы можем воспользоваться сервисом Яндекс.XML и отправить запрос на получение сниппета нашей страницы. В ответ мы получим XML-документ, в котором будет содержаться информация о сниппете нашей страницы. Мы можем распарсить этот XML-документ и получить нужные нам данные: заголовок и описание страницы.
Таким образом, используя Яндекс.XML и парсер сниппета, мы можем получать информацию о своих страницах в поисковой системе Яндекс и анализировать ее для улучшения SEO-оптимизации нашего сайта.
- Преимущества использования Яндекс.XML:
- Доступ к актуальным данным о своих страницах в Яндексе.
- Возможность анализировать и оптимизировать сниппеты своих страниц для лучшей видимости в поисковой выдаче.
- Обратная связь со сниппетами — можно увидеть, какие заголовки и описания привлекают больше кликов и настроить их соответствующим образом.
Таким образом, использование Яндекс.XML на примере парсера сниппета поисковой системы Яндекс является важным инструментом для SEO-оптимизации сайта и повышения его видимости в поисковой выдаче Яндекса.
Что такое Яндекс.XML и как его использовать
Использование Яндекс.XML является одним из ключевых элементов стратегии по оптимизации сайта для поисковых систем. Он предоставляет возможность улучшить видимость и индексацию сайта в Яндексе, что является особенно важным для российскоязычных сайтов и аудитории.
Для использования Яндекс.XML необходимо создать XML-файл, который содержит информацию о каждой странице сайта. В этом файле можно указать такие параметры, как приоритетность страницы, частота ее обновлений, дата последнего изменения, а также исключить индексацию некоторых страниц или разделов сайта.
XML-файл Яндекс.XML может быть создан вручную или с помощью специализированных инструментов, таких как Яндекс.Вебмастер или сниппеты вручную. После создания файла он должен быть загружен на сервер сайта и зарегистрирован в Яндекс.Вебмастере. После этого Яндекс будет периодически обращаться к файлу для обновления данных и индексации сайта.
Использование Яндекс.XML может значительно улучшить позиции сайта в результатах поиска Яндекса. Он позволяет более точно указать поисковой системе на важные страницы сайта, облегчает индексацию и повышает шансы на позиционирование в выдаче.
Как работает парсер сниппета поисковой системы Яндекс?
Когда пользователь вводит запрос в поисковую систему Яндекс, система происходит следующий процесс. Вначале Яндекс обращается к своей базе данных, где хранится множество веб-страниц. С помощью алгоритмов поиска Яндекс определяет, какие страницы наиболее релевантны запросу пользователя.
Затем следует этап формирования сниппета – краткого описания и заголовка страницы, которые отображаются в результатах поиска. Для этого Яндекс использует парсер сниппета, который извлекает информацию из кода страницы. Парсер сниппета анализирует содержимое страницы, ищет заголовки, мета-теги и ключевые фразы, которые могут быть полезны для пользователей.
Парсер сниппета также определяет, какие фрагменты текста на странице будут наиболее информативными для отображения в сниппете. Он может выделить ключевые слова и фразы, использовать их в описании страницы и добавить форматирование, такое как жирный шрифт или курсивность, чтобы выделить важную информацию.
Когда парсер сниппета завершает свою работу, Яндекс отображает сниппеты в результатах поиска. Пользователь видит краткую информацию о странице – заголовок, описание и URL. Это помогает пользователю оценить релевантность страницы и принять решение о ее посещении.
- Преимущества парсера сниппета:
- Позволяет пользователю быстро получить информацию о странице;
- Помогает оценить релевантность страницы;
- Сниппет может включать ключевые слова и фразы, привлекающие внимание пользователей;
- Добавляет информативность и удобство при просмотре результатов поиска.
Пример использования Яндекс.XML и парсера сниппета
В этой статье мы рассмотрели пример использования Яндекс.XML и парсера сниппета для повышения эффективности SEO оптимизации. Рассмотренные методы помогут вам повысить видимость вашего сайта в поисковых системах, в том числе на Яндексе.
Первым шагом в использовании Яндекс.XML является настройка API-ключа и формирование запроса к серверу. Мы рассмотрели различные параметры запроса, такие как тип сниппета, количество выдачи, язык и страна, а также возможность получения данных по URL или поисковому запросу.
Далее мы рассмотрели процесс парсинга ответа от сервера. С помощью парсера сниппета мы извлекли информацию о заголовке, описании и ссылке на страницу из поисковой выдачи. Затем мы использовали полученные данные для составления сниппета на своей странице с целью привлечения пользователей и повышения кликабельности.
Пользуясь данными, полученными из Яндекс.XML, можно провести дополнительные исследования и анализировать результаты для улучшения своей стратегии поисковой оптимизации. На основе этих данных можно определить, какие страницы имеют лучшую видимость и какие фразы релевантны вашему сайту.
Использование Яндекс.XML и парсера сниппета дает вам возможность контролировать и улучшать информацию, отображаемую в поисковой выдаче. Это помогает вам привлечь больше органического трафика на ваш сайт и улучшить его позиции в рейтинге поисковых систем.